Kiddom - On Demand Ingestion
Context
Kiddom is an education platform that delivers high-quality curriculum content through online experiences designed to support teachers. The platform includes both open-source and proprietary curricula, and each content provider distributes materials in a different format. To make this content easier to navigate in a digital classroom, Kiddom instructional designers reshape and enrich source materials. This work also includes creating custom lessons, activities, and learning experiences that align with Kiddom’s enhanced classroom model.
My Role
- Designed the ingestion workflow and data transformation approach.
- Implemented the loading, parsing, and transformation pipeline in TypeScript.
- Built the UI workflow used by instructional designers to configure folder and file naming conventions, including a pattern input that used pills to represent structural tokens.
- Worked with instructional designers to define a folder and document structure that could be mapped into the platform’s curriculum schema.
Problem
Like many CMS platforms, Kiddom includes a Builder for entering curriculum content. At the time, however, the Builder did not support revision history or versioning. This created friction for curriculum developers and instructional designers, who needed collaborative editing and feedback. Their workaround was to draft content in Google Drive (for comments and revisions), then manually copy it into the Builder section by section. The process was slow, repetitive, and error-prone.
Constraints
Project constraints limited the solution space:
- As the assigned developer, I could not create a standalone tool outside the existing internal stack.
- The first milestone required mapping Google Drive content structures (defined with instructional designers) into Kiddom’s platform data model.
- Google Drive folder structures were inconsistent across teams and providers.
- Due to permission and access policies, the solution had to live inside an existing internal tool.
Decision
For the initial release, we used a generalized fixed content structure for mapping. We implemented the workflow inside an existing internal tool that already handled user permissions and access control.
UI Design Decisions
- Add a component for the folder/files naming configuration.
- Because this is an on-demand process used by non-technical users, the UI exposes each step so users can adjust file naming and folder structure as needed.
- The flow provides three auditable stages: Loading, Parsing, and Transforming.
Technical Decisions
At the time, to reduce implementation friction and meet timeline constraints, I handled loading and parsing on the frontend.
The ingestion process worked by retrieving Google Drive files through their exportable HTML representation. The parser then analyzed the document structure and segmented the content using heading hierarchy as anchors (H1–H4). The first output was an intermediate JSON representation of the document content. After that, a mapping layer transformed that intermediate structure into the simplified tree-style JSON expected by the platform importer.
The algorithm followed these steps:
- Load each Google Drive document as exported HTML.
- Traverse the DOM and identify heading elements (H1, H2, H3, H4).
- Use the heading hierarchy to determine content boundaries and nested sections.
- Slice the document into semantic blocks based on those boundaries.
- Generate an intermediate JSON representation containing the section titles and associated content.
This approach allowed loosely structured documents written by instructional designers to be converted into a normalized format compatible with Kiddom’s internal curriculum schema.
Before and After Transformation
Intermediate document representation
{
"title": "Lesson 11",
"sections": [
{
"level": "h2",
"title": "Warm Up",
"content": "...",
"children": [
{
"level": "h3",
"title": "Instructions",
"content": "..."
}
]
}
]
}Mapped simplified tree for import
{
"type": "lesson",
"title": "Lesson 11",
"children": [
{
"type": "section",
"title": "Warm Up",
"children": [
{
"type": "richText",
"title": "Instructions",
"content": "..."
}
]
}
]
}Pattern-Based File Matching
A useful UI detail was a pattern input component that represented expected file structure as pills, making the naming convention more legible for non-technical users. This helped users define how files should be matched before ingestion started.
For example, a pattern like G{grade}_U{unit}_L{lesson}.json could be used to match a file such as G5_U3_L11.docs by identifying the structural tokens embedded in the filename.
If I were implementing this today, I would move ingestion to a backend-first pipeline: queue jobs, parse and transform content in worker processes, and expose progress and status APIs to the frontend.
Tradeoffs
- We focused on optimizing loading and parsing in pure TypeScript.
- Because the workflow is frontend-dependent, rendering thousands of files can block the UI.
- To mitigate this, we limited visible file output, kept imported payloads lightweight, and discarded unnecessary data early.
Outcome
The tool reduced the manual copy‑paste workflow used by instructional designers and proved valuable enough to justify a roadmap for a more scalable Version 2 ingestion system.
What I Would Do Now
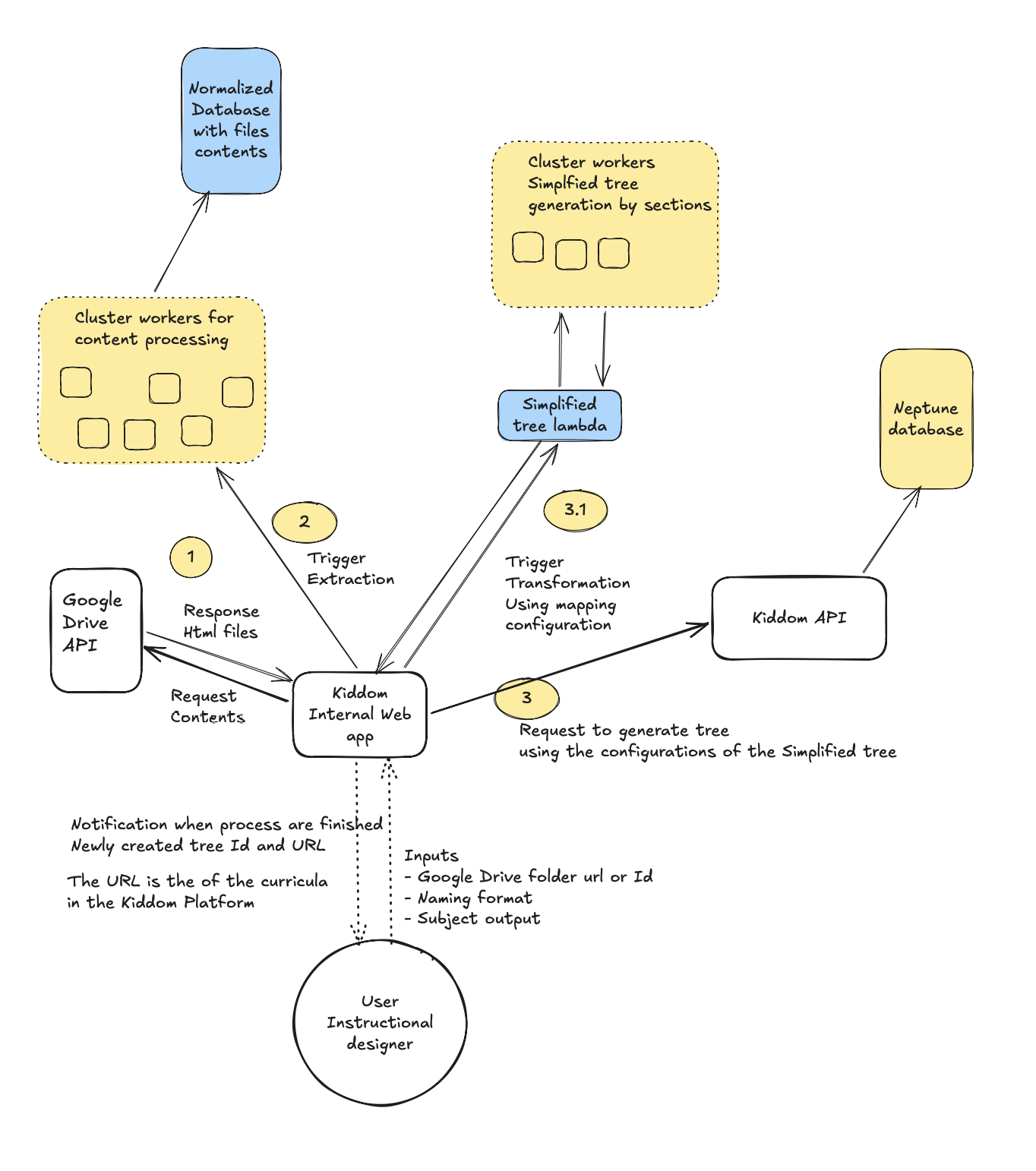
- Move loading, parsing, and transformation to asynchronous backend jobs for reliability at scale.
- Keep the frontend focused on orchestration: submit ingestion requests, surface progress, and show import validation results.
- Add robust retries, failure recovery, and audit trails for each ingestion run.
- Add clear versioning and revision support to reduce dependence on external editing tools.
- Define and enforce a canonical folder/file convention before ingestion starts.